When diving into the world of NoSQL databases, understanding when to normalize and when to denormalize your data structures is crucial. This blog post explores the trade-offs between normalizing and denormalizing, drawing from real-world scenarios during my time at KAIKAKU and other projects.
Before we proceed, here’s an example of normalized and denormalized NoSQL data:

Looks Can Be Deceiving - Why Normalization Isn’t Always the Answer
At KAIKAKU, we initially opted for a normalized NoSQL data model, traditionally praised for ensuring data integrity, consistency, and ease of maintenance. A normalized schema seemed more practical for our databases which, at the time, would frequently be directly accessed by our developers via the Azure Cosmos DB Portal. However, as our systems scaled to accommodate hundreds to thousands of daily requests from external services like our self-service kiosks, the limitations of this model became increasingly apparent.
While normalization did offer an added layer of data organisation and seemed ideal for spotting errors during direct interactions with Cosmos DB for debugging, it came at the cost of increased code complexity, slower performance, and more significant challenges in handling network issues.
Normalization vs. Denormalization: Choosing the Right Approach
Frank van Puffelen, an Engineer at Google with over 10 years of experience working on Firebase, shares an example of when a team had to make a key data design decision between adopting a normalized vs denormalized approach. source
“Most developers I see will keep the profile information separate and just keep the user UID in the post as an unmanaged foreign key. This has the advantage of needing to update the user profile in only one place when it changes. […] But one of the first bigger implementations I helped with actually duplicated the user data over the stories. […] they argued many good reasons why they needed the historical user information for each story.”
The choice between normalization and denormalization hinges on several factors:
Multiple queries vs one larger query: At KAIKAKU, we found that a single, larger query (denormalized) often made more sense over multiple smaller queries, especially in unstable network conditions. This simplicity became crucial in our robotics operations, where managing a single point of failure was considerably more straightforward than troubleshooting multiple.
Per-query performance: Although a normalized schema can offer faster query responses by targeting smaller datasets, this wasn’t critical for our kiosk users, who generally would not notice loading times between sessions (as there would be a buffer of a few seconds between users).
Data consistency: Working directly within Cosmos DB, a normalized schema initially helped us manage data safely without unintended consequences across the system. However, this benefit was made redundant as we began to implement custom in-house dashboards for data management.
Complexity of application-side error handling: A normalized schema can make error handling more complex, especially when dealing with network issues. In contrast, a denormalized schema simplifies error handling by reducing the number of network calls to just one.
I would like to demonstrate complexity of application-side error handling as it was a change that we found particularly beneficial at KAIKAKU. Below is an example Python script that I prepared to showcase how taking on a normalized approach can increase client-side code complexity:
| |
Remember, as Jeff Atwood, the founder of Stack Exchange, wisely said:
“The best code is no code at all.”
The more error handling you can avoid, the better!
Why We Embraced A Denormalized Data Model
For us, the benefits of denormalization boiled down to managing network issues in a more streamlined way by monitoring a single API call’s success or failure. This approach proved particularly effective for our kiosk app which would either load all the data before the user began navigation or report an issue and instruct users to try another kiosk. The decision to immediately report any network issues to the user at the point of interaction helped avoid further frustrations and time wasted.
Just imagine if you spent all that time preparing your order only to find that the kiosk couldn’t process it due to a network issue!
A word of caution: Despite its benefits, denormalization introduced challenges with stale data and redundancy. However, these were trade-offs we could accommodate given our emphasis on uptime.
Below is a diagram illustrating potential data sync issues in a denormalized schema. The diagram shows a simplified example from KAIKAKU’s Fusion robot:
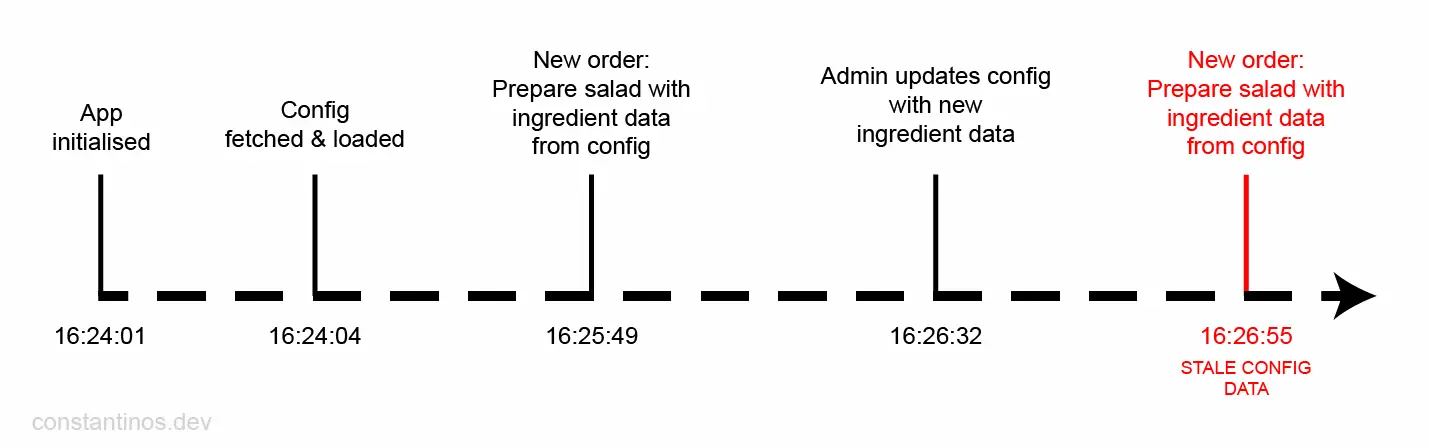
Since we do not re-fetch the config on every new order (as it can have quite a large size), the robot will continue to use the old config until the next restart. This can easily be mitigated through a simple polling mechanism, or a more complex event-driven system.
Consider the following Python snippet, which showcases potential data synchronization challenges in a denormalized schema and the added complexity in error handling with a normalized approach:
| |
In the example above, the normalized approach significantly slows down new order processing, while the denormalized approach optimises for quick handling at the cost of increased application startup time.
Closing Thoughts
The tech industry often favours a denormalized approach, but it’s not universally the best choice. For applications where data accuracy is paramount, a normalized schema might be preferable - unless you are prepared to implement data synchronization mechanisms such that changes to the cloud data are propagated through your software.
Setting up or revising a NoSQL database isn’t just a matter of technical feasibility - it’s about ensuring your data management strategy aligns with the real-world dynamics of your application. If you have questions or would like to discuss further, don’t hesitate to get in touch.